
現代社会において、AI(人工知能)はますます多くの分野で活躍しています。
例えば、私たちが毎日使用するスマートフォン、音声アシスタント、さらには自動運転車に至るまで、AI技術が深く根付いています。
AIがこれらの驚くべき能力を持つ理由の一つが、機械学習という技術にあります。中でも「教師あり学習」という方法は、AIを賢く育てるための重要な手段となっています。
今回は、この「教師あり学習」について深く掘り下げていき、さらにAIの学習を支える「ラベリング」作業がどれほど重要であるかを探ります。
教師あり学習?ラベリング?
1つずつ解説していくよ!
機械学習とは?AIを賢く育てる技術の基礎
AI(人工知能)の進化を支えている技術の一つが「機械学習」です。
機械学習は、コンピュータが人間のように学び、経験を積みながら自動的に改善するプロセスを指します。簡単に言えば、機械学習は「データを使って、コンピュータが予測や判断をできるようにする技術」です。

例えば、私たちが日々使っているスマートフォンやパソコンでの顔認識、音声認識、さらにはネットショップでの商品の推薦なども、機械学習によって実現されています。
機械学習の目標は、コンピュータがデータを分析し、そこから得たパターンを元に新しい情報を予測することです。
機械学習には大きく分けて「教師あり学習」、「教師なし学習」、「強化学習」の3つのアプローチがありますが、今回はその中でも最も一般的で、AIが「正解」を学ぶための方法である「教師あり学習」に焦点を当てていきます。
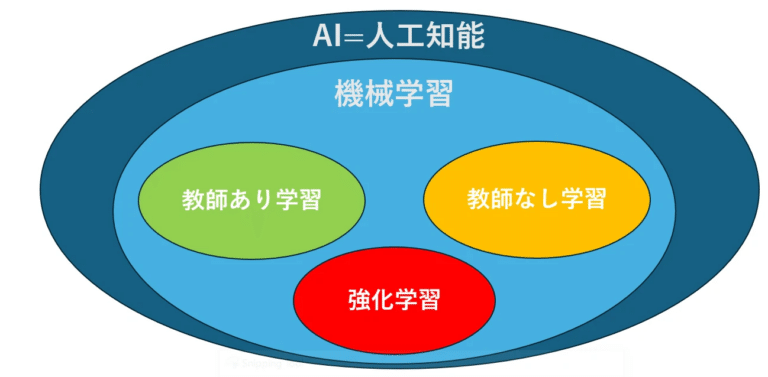
教師あり学習とは?AIに「答え」を教えるプロセス
教師あり学習とは、機械学習の一つの手法で、AIが「正解」を学ぶ過程を指します。
この方法では、あらかじめ正解がわかっているデータをAIに与え、そのデータの特徴を学習させます。これにより、AIは新たに与えられたデータに対して予測や分類を行うことができるようになります。
例え話で学ぶ教師あり学習
例えば、「猫」の画像をAIに認識させるシナリオを考えます。
猫の画像には「猫」というラベルを付け、犬の画像には「犬」というラベルを付けます。このラベルをもとに、AIは猫と犬の違いを学びます。
具体的には、耳の形、目の位置、毛の質感などを数値化し、それぞれの特徴を抽出していきます。その結果、AIは新たな画像が入力されると、それが「猫」か「犬」かを判断できるようになります。
これが教師あり学習の基本的なプロセスです。


その他具体例
教師あり学習は、さまざまな場面で活用されています。以下にいくつかの具体的な使用例を紹介します。

ラベリング:AI学習の根幹を支える作業
教師あり学習において、AIが学ぶためには「ラベル」と呼ばれる正解が必要です。このラベル付け作業が「ラベリング」と呼ばれ、AIにとって非常に重要な役割を果たします。
ラベリングとは?
ラベリングとは、データに対して正しいタグや情報を与える作業のことです。
画像データであれば、画像に写る物体(猫、犬、車など)を特定してテキストで記述したり、音声データであれば、その内容をテキスト化したりします。ラベリングが正確でないと、AIは学習できません。
ラベリング作業の難しさ
一見、ラベリング作業は単純なように見えますが、実際には非常に手間のかかる作業です。
特に、データ数が膨大である場合や、データに含まれるラベルが複雑な場合、専門的な知識が求められることがあります。
例えば、医学画像や自動運転車のデータなどでは、高度な知識を持つ専門家がラベルを付ける必要があります。
学習データをたくさん用意するためには、その分ラベリング作業を行う必要があるんですね
実際、AIモデル作成のために80%の時間をラベリングに費やすというデータもあるよ

ラベリングの重要性:AI学習の精度を高める
ラベリング作業がAI学習において非常に重要である理由は、正確なラベルがなければAIが正しく学習できないからです。
以下に、ラベリングがAI学習においてどのように影響を与えるのか、いくつかのポイントを挙げてみましょう。
- 学習データの質向上
大量のデータが存在していても、それらのデータに正確なラベルが付けられていなければ意味がありません。正確なラベルを付けることで、AIはより効果的に学習し、精度の高い予測を行うことができるようになります。
- モデルの性能評価
ラベリングされたデータを使用して学習モデルを評価することで、AIの精度や性能を客観的に測ることができます。正確なラベルがあれば、AIがどれだけの精度で予測を行っているかを把握でき、改善点を見つけやすくなります。
- AIの信頼性向上
正しいラベリングが行われたデータで学習を進めることで、AIが予測する結果に対する信頼性も向上します。ビジネスや医療など、重要な分野で活用されるAIにおいては、予測の信頼性が特に重要です。
ラベリングの課題と解決策
ラベリングには多くの課題があります。そのいくつかを見ていきましょう。
これらの課題を解決するために、以下のような取り組みが進められています。

教師あり学習の将来性と展望
教師あり学習は、今後ますます重要な技術となっていくと考えられます。
特に、深層学習(ディープラーニング)の発展により、AIはより複雑なタスクをこなせるようになっています。しかし、AIが人間の能力を超えるためには、より高度な教師あり学習とラベリング技術が求められるでしょう。

今後の技術革新として、以下のような進展が期待されています。
教師あり学習のまとめ
教師あり学習は、AIを賢く育てるために不可欠な技術です。
正確なラベリングによって、AIは新しいデータに対して的確に予測や分類を行えるようになります。これからも教師あり学習の技術は進化し続け、より高度なAIが生まれてくるでしょう。
ラベリングは一見地道で手間のかかる作業ですが、AIの精度を高めるために欠かせない重要なプロセスです。
教師あり学習とラベリングが進化することで、より賢いAIが私たちの生活に役立つ未来が待っています。